好像每次转身都有一篇论文提到 CRISPR-Cas9. 场爆炸的速度有多快? 没有什么比数据更值得一探究竟! 在下面的直方图中,X 轴上的每个条形是一周(任意从 2011 年末开始),Y 轴是 Pubmed 搜索“CRISPR AND Cas9”中的论文数量(旁注:需要包括CRISPR 在搜索中是因为“Cas9”虚假地包含了一些实验室的结果,这些实验室喜欢将 caspase 称为“CAS号”,例如 caspase 9 = Cas9,caspase 3 = Cas3).
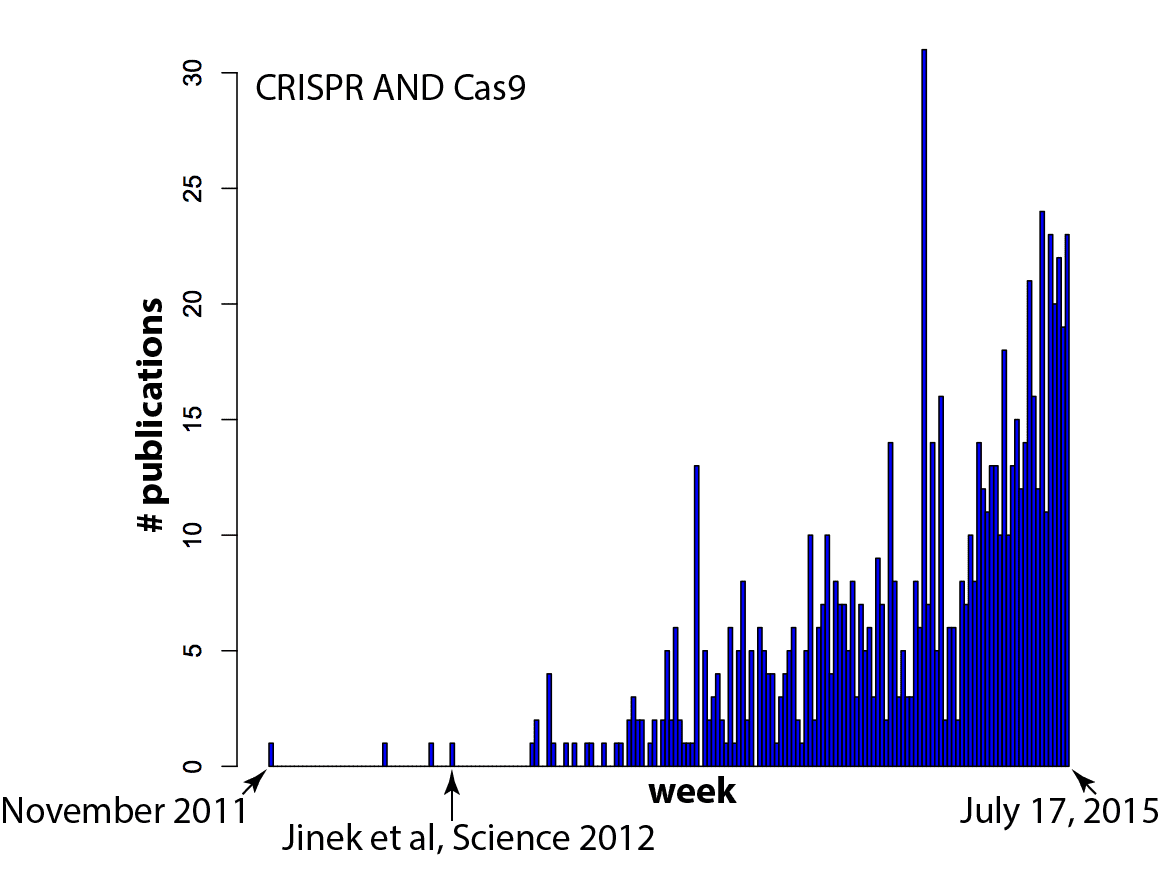
你的预感是对的——每次你转身都会有一篇新论文提到 CRISPR/Cas9:几篇 每天, 事实上。
我认为(希望)这意味着我们正在达到一个临界点。 目前流行在整篇论文中使用“Cas9”,即使该系统被用作生物学工具而不是它本身的工作重点,因为它引起了编辑的注意。 但随着越来越多的团体使用 Cas9, 基因编辑 将变得司空见惯。 例行公事,甚至。 这正是应该发生的事情! 你能想象现在有一篇论文对他们如何使用凝胶电泳分离吗? 蛋白质, 或 PCR 和限制 酶 克隆一个 基因? 颠覆性技术很快成为工具箱的一部分,这是自然而然的过程。 例如 RNAi,不久前它完全颠覆了生物学,现在被大多数人例行使用,没有大惊小怪 细胞 生物实验室。 将上面的图与 RNAi 的等效图进行比较(此处搜索的是“RNA 干扰”由于搜索“RNAi”的复杂性,因为它还会发现其他命中 病毒 RNA称为“RNA-one”。 另请注意,在 Andy Fire 1998 年 Nature 论文之前存在一些误报)。
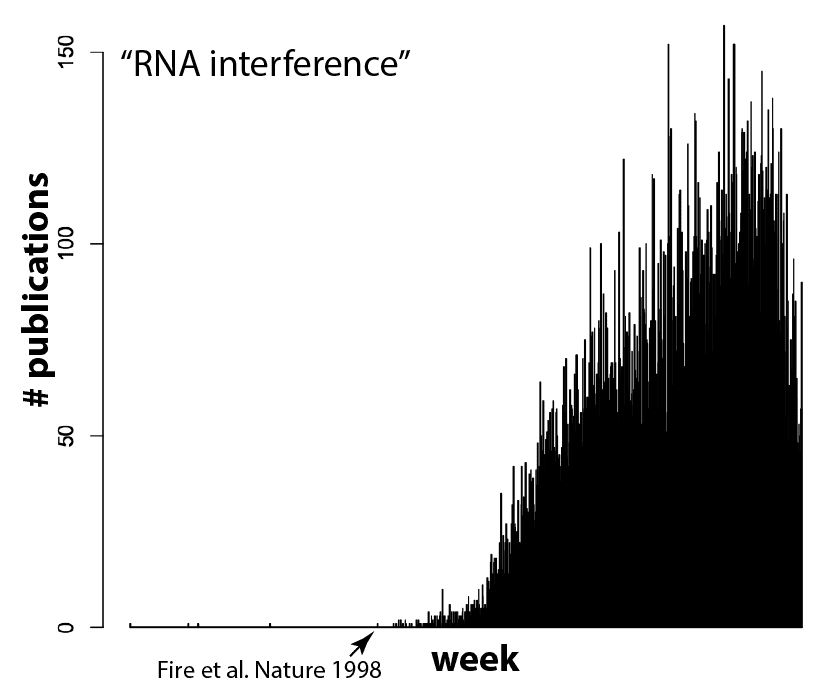
我期待着 CRISPR-Cas9 变得像 RNAi 一样普遍的那一天,因为这意味着我们已经进入了一个新的生物学时代。 想知道那个保守的遗传元件有什么作用吗? 删除它。 想知道保守残基在您最喜欢的蛋白质中的作用吗? 变异 它在您感兴趣的有机体中。 没什么大不了!
那将是一段不可思议的时光。 我是为了目的地,而不是车辆。
对于那些感兴趣的人,这里是如何生成直方图
(下载用于 pubmed 搜索的 medline 格式记录)
# medlinedates.py
#!/usr/bin/env python
from Bio import Medline # requires Biopython
import datetime
import sys
fin = sys.argv[1]
with open(fin) as p:
records = Medline.parse(p)
for record in records:
d = record['DA']
d = datetime.date(int(d[:4]), int(d[4:6]), int(d[6:8]))
print d.toordinal()
-
(在命令行上)
$ medlinedates.py [medline format file you downloaded] > dates.txt
-
(在 R 中)
# plotdates.R
d<-read.table("dates.txt", header=F)
ranges<-append(c(seq(min(d$V1), max(d$V1), by = 7)), max(d$V1))
hist(d$V1, breaks=ranges, freq=TRUE, col="blue")